It would be great to hear if anyone relies on the IATI Registry “Data Search”, and specifically the file-level set up that some publishers follow: one IATI XML file per recipient-country.
The underlying logic, which I think has been in place since day one of IATI, is that the Data Search can give us all files that are about a certain recipient country, for example these 46 files for Bangladesh:
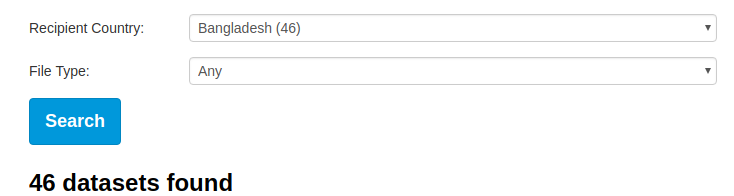
However - I think it’s well-known that this search is not definitive.
If we check d-portal (for example) we can see that 185 publishers actually have activities with this same recipient-country:
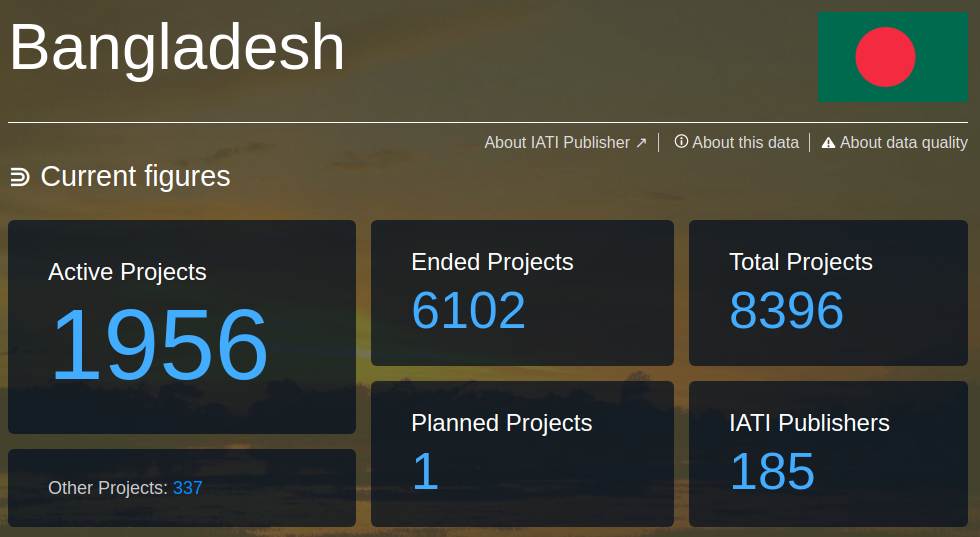
This is a big mismatch. It’s because many publishers might include all their activities in one / a few file(s) (Netherlands @Herman; Canada @YohannaLoucheur ) or also have multi-country activities that may be in a regional file (DFID @JohnAdams).
Therefore - what’s the point of the XML file-per-country and/or the IATI Registry Data Search? Does this actively help data users?
Added to this, is that the recipient-country filter on the Registry is populated with quite a few non-obvious entries:
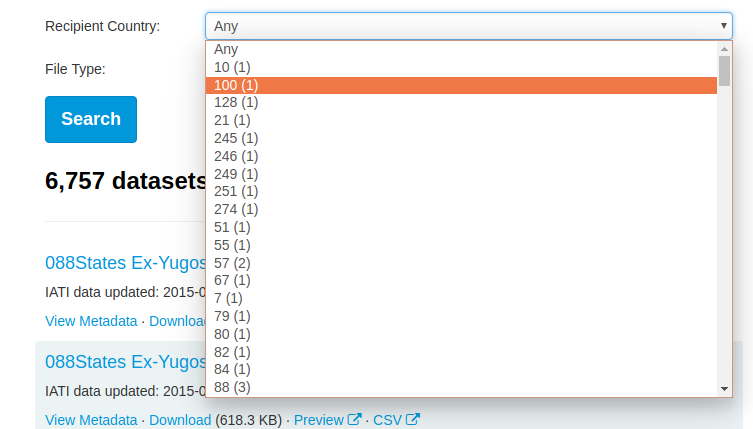
Thoughts welcome. I can understand how something like the Datastore might eventually fix this, but we should also think about the Here and Now: there might be someone trying to use IATI data and quickly finding this not useful.