I’m working with an organisation who wish to publish results data.
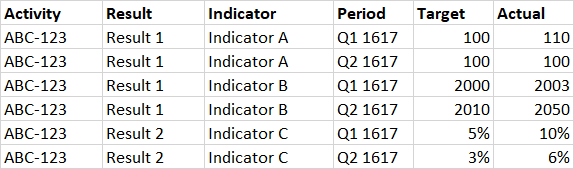
For any indicator, there will be multiple measurements (periods) that provide target and actuals, like this:
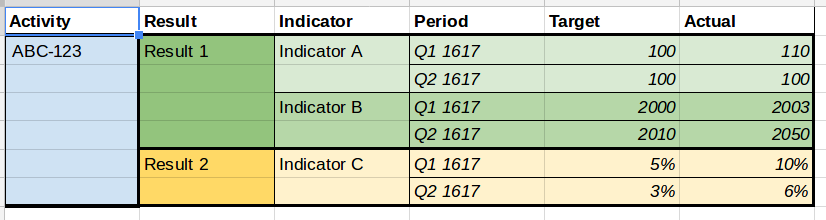
The standard allows this:
- a result can have one or more indicator
- any indicator can have more than one period (which then holds the target and actual data)
So far so good. But… how do we actually maintain this data, for the production of IATI. And then - use it!
Missing in the schema is the ability to somehow identify the result(s) and indicator(s), meaning that whilst you might want to say in the above model:
the actual value 100 relates to the period Q2 1617, and contributes to Indicator A, which is a part of Result 1.
It doesn’t seem possible to declare the concepts of Result 1 and Indicator A.
(the ref attribute of transaction might be a good analogy here)
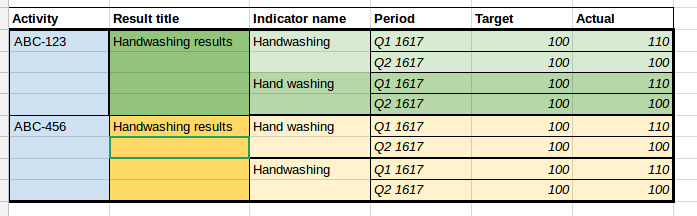
This becomes a real difficulty when you’re managing data on multiple activities, all with many results, a range of indicators and various measurement periods.
Of course, it’s possible to do this directly in the XML, but the struggle is how to manage this in the lead up to publishing - whether spreadsheets, in house systems or elsewhere. The Aidstream interface would enable this multi-multi recording, but I assume there’s some database behind it - @anjesh , do you provide a databse key (or similar) for the above elements?
And - at the other end, if someone wants to convert some XML to a spreadsheet / other format - how do packages then handle such multi-multi relationships, with IDs?
@Herman @rolfkleef @pelleaardema what’s your experience?
@SJohns @mikesmith @rbesseling did this come up in the CSO work on results?