Hi Everyone!
Firstly, Bill is absolutely right to say that invalid data shouldn’t be banned, and I think that it might be helpful to flesh out one consideration so that people can reflect on it. I’m not wedded to the following idea, but it’d be interested to hear @siemvaessen and @Herman’s thoughts as users, and it might move this conversation along to other, better proposals 
Technical implementation
The registry gets a new protected field (i.e. set by sys, not the publisher) that has the following values:
-
1: ‘invalid_xml’ - xml validation fails
-
2: ‘invalid_IATI’ - xmllint schema validation fails
-
3: ‘invalid_content’ (arithmetic errors etc.) - opinionated content validation fails
-
4: ‘healthy_dataset’ - all good
Call this field ‘Health’
There is a daily batch process which does the following on every registered dataset:
# This is pseudocode!
def daily_check(dataset):
if dataset is newly_registered:
# the 'validate()' method would be a xmllint+ content validator
dataset.health = validate(dataset)
add_to_md5_cache_register(dataset)
# then do any initial setup of the dataset necessary
else:
if md5(dataset) not in md5_cache_register:
dataset.health = validate(dataset)
add_to_md5_cache_register(dataset)
# other operations such as updating the activity count and `IATI data updated` time field
else:
# record somewhere that the check has been run
In plain english: this checks if a dataset has been recently registered (which is available in CKAN metadata).
- If the dataset has been recently registered, the method runs a validator to define the ‘health’ field and adds an md5 hash string for that activity to a register.
- If it hasn’t, the method checks to see if the md5 hash exists already
- If it doesn’t, the method runs the checks and updates the cache
- If it does, then nothing happens
In every step except the last one, the IATI Data Updated field would be updated, possibly along with other fields (see below for why)
So far, so good? (@dalepotter, @hayfield - please let me know if I’m making naive assumptions about what is possible in CKAN.)
Direct uses in the IATI infrastructure
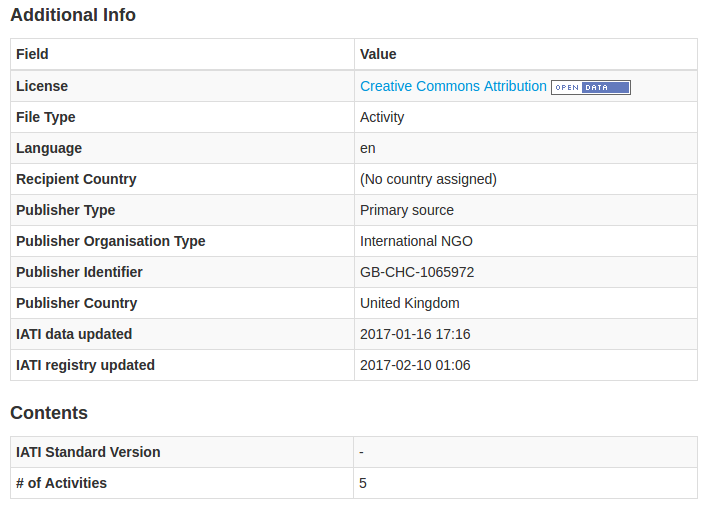
Consider the following metadata from an IRC_UK activity:
Imagine that ‘Health’ now sits in the Contents section (as does IATI data updated, ideally), and that all of the fields in that section are set by sys, not publisher, in a method similar to the one above.
This has the following advantages:
- The dashboard, datastore, and other systems which use the registry API could just decide to retrieve activities which have a
health rating of 3 or higher, and simply count the files in the other categories for the sake of gathering statistics (without trying to parse them, or spend computation time on validating them).
- OIPA / other parsers could do something similar.
- No transparency is lost, i.e. all files are still accessible, and users who want to dredge through the invalid data can attempt to (though I’d say there’s little value, particularly for
health < 2.
- Because the
IATI data updated field would be trustworthy, a lot of computation time throughout the technical ecosystem could be saved; I’m sure the dashboard / datastore / OIPA run times could be cut in half, or possibly down below a quarter, just by skipping any datasets that haven’t been updated since their last run.
- With the right UX considerations, users could be given the choice between ‘clean’ IATI and ‘comprehensive’ IATI, where the former is good for data analysis, and the latter is good for transparency and accountability.
Thoughts? I look forward to some debates about this at the TAG