Question: where can I get a list of organisation references for IATI publishers?
Answer - here’s a list, which took some steps to produce
Sounds simple? Well, it took us a few steps to get to this (big thanks to @bjwebb):
-
We first looked at the IATI Registry. Each publisher has a freetext field for their organisation reference. We found this to be inconsistent and unreliable: the dashboard confirms this.
-
we then looked Activity data. The reporting-org reference is useful here. But - this is repeated, and sometimes different. It seemed a lot of overhead to check 4500+ files for around 500 identifiers.
-
so, finally, we landed at the Organisation file. Big Surprise!
Yes. When discovering the preferred organisation reference for an IATI publisher, we found the Organisation files to be the best source. Specifically, we looked for instances where:
reporting-org/@ref matches the identifier in organisation-identifier (or iati-identifier in versions 1.0x)
(it’s entirely possible and feasible to reference many organisations in a single org file, but we focused on matches between the publisher and org reference initially)
We took a look into this (in July 2017), and found:
- Of 555 IATI publishers, there were 406 IATI organisation files (73% of publishers provide an Org file)
- Of these 406 publishers, 392 organisation identifiers match the reporting-org/@ref (97%)
So - when a publisher provides an Org file, it’s highly likely that this will be a definitive source for their organisation reference
So far, so good.
Next, we then took a look at the prefixes for these references, to understand if these were available via the org-id project (which IATI supports). On doing this, we found:
- Of 392 “matching” organisation identifiers, 333 started with a “recognised” prefix (85%)
So again - a trend seems to be that definitive, and standardized / useful organisation references are also highly likely via the IATI Org file.
What Next?
It seems obvious:
- all publishers should provide an Org file
- the definitive organisation reference for a publisher should be maintained in the Org file
It doesn’t seem a lot of effort to get to nearly 100% coverage in the above metrics. It would be useful to hear thoughts from others.
Last notes:
-
this isn’t a list of all the organisations mentioned via IATI data: we wanted to focus initially on the growing list of publishers
-
how such a list (if it is a list - @TimDavies thinks it’s more of a cache) is published, maintained and used is another topic. In doing this research, we output the identifiers as a spreadsheet, but also looked at how the IATI Organisation standard could be used.
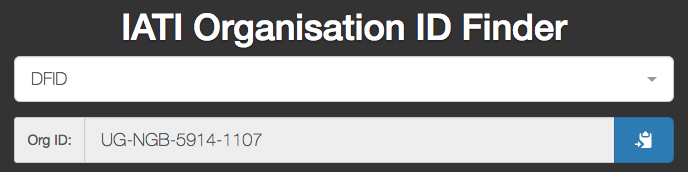 Apparently this xml has that id
Apparently this xml has that id  Funnily enough, I did exactly the same search as you last week, and found the same data issue. But instead of taking responsibility for the problem and fixing it myself, I was able to trace where the problem was, by clicking the source link:
Funnily enough, I did exactly the same search as you last week, and found the same data issue. But instead of taking responsibility for the problem and fixing it myself, I was able to trace where the problem was, by clicking the source link: